Введение
В большинстве современных протоколов блокчейна каждый участник цепи скачивает и проверяет каждую транзакцию. Это естественным образом ограничивает сверху количество транзакций, которые протокол может выполнять за единицу времени: не больше, чем может скачать и выполнить средний участник цепи.
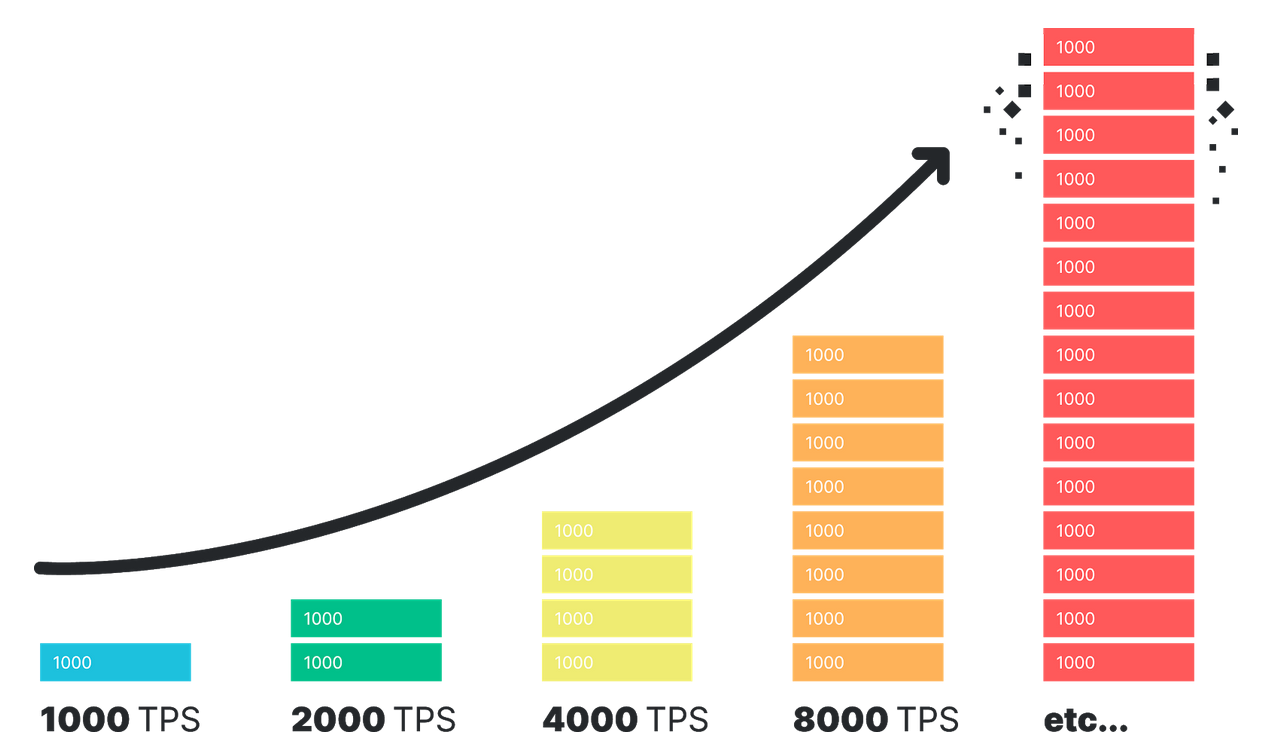
Ключевая идея шардинга заключается в том, что вместо того, чтобы каждая транзакция в сети была выполнена каждым участником, только подмножество участников выполняют каждую транзакцию. Для достижения этой цели все состояние цепи (аккаунты, контракты, данные) разбиваются на несколько непересекающихся интервалов, которые называются “шардами”; каждый участник сети назначается на один или больше шардов, и скачивает и выполняет только транзакции, относящиеся к своим шардам.
Когда участникам сети приходится взаимодействовать с шардом, на который они не назначены, они в общем случае не могут получить и проверить всю историю этого шарда.
Это приводит к потенциальной проблеме: без загрузки и проверки всей истории участник не может быть уверен, что состояние, с которым он взаимодействует, — это результат валидной последовательности блоков и что такая последовательность действительно является канонической цепочкой в этом шарде. В прошлой статье я показывал, почему этой проблемы нет в нешардируемых блокчейнах.
Сначала мы разберем простое решение этой проблемы, которое предлагают многие протоколы, затем проанализируем, как оно может быть скомпрометировано, и опишем, какие способы устранения этой проблемы предлагаются, их сильные и слабые стороны.